
Understanding RAG in the Context of Azure AI
RAG is designed to make generative AI more grounded and reliable. While most large language models generate answers purely from their training data, RAG introduces a mechanism that retrieves relevant content from trusted data repositories before generating a response. This ensures that outputs are not only contextually appropriate but also factually accurate. Within Azure AI Foundry, RAG functions as a pipeline where information flows dynamically between the retriever and the generator.
The architecture relies on three conceptual steps: indexing, retrieval, and generation. In the indexing phase, enterprise data such as manuals, reports, or emails is stored and structured within Azure AI Search. Each document is transformed into smaller segments and represented through vector embeddings using Azure OpenAI Embeddings API.
When a user submits a question, the retrieval phase begins as Azure AI Search identifies the most relevant content segments based on semantic similarity. These results form the contextual input that guides the generator, typically an Azure OpenAI model such as GPT-5, in producing the final response. This design makes the system both dynamic and verifiable. At Microsoft Ignite, there is a chart illustrating how RAG works to support AI services.
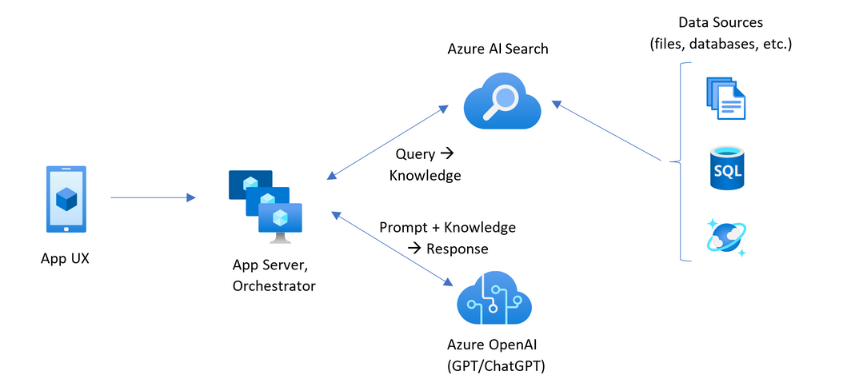
Source: Learn Microsoft
How It Works in Practice on Azure AI Foundry
Within Azure AI Foundry, the RAG process becomes easier to build and scale because the platform unifies vector search, prompt orchestration, and monitoring into a single managed workspace. Data preparation is the first critical step. Enterprise files are converted into text embeddings using Azure OpenAI models such as text-embedding-ada-002. These embeddings are then stored in Azure AI Search, which acts as the retriever index.
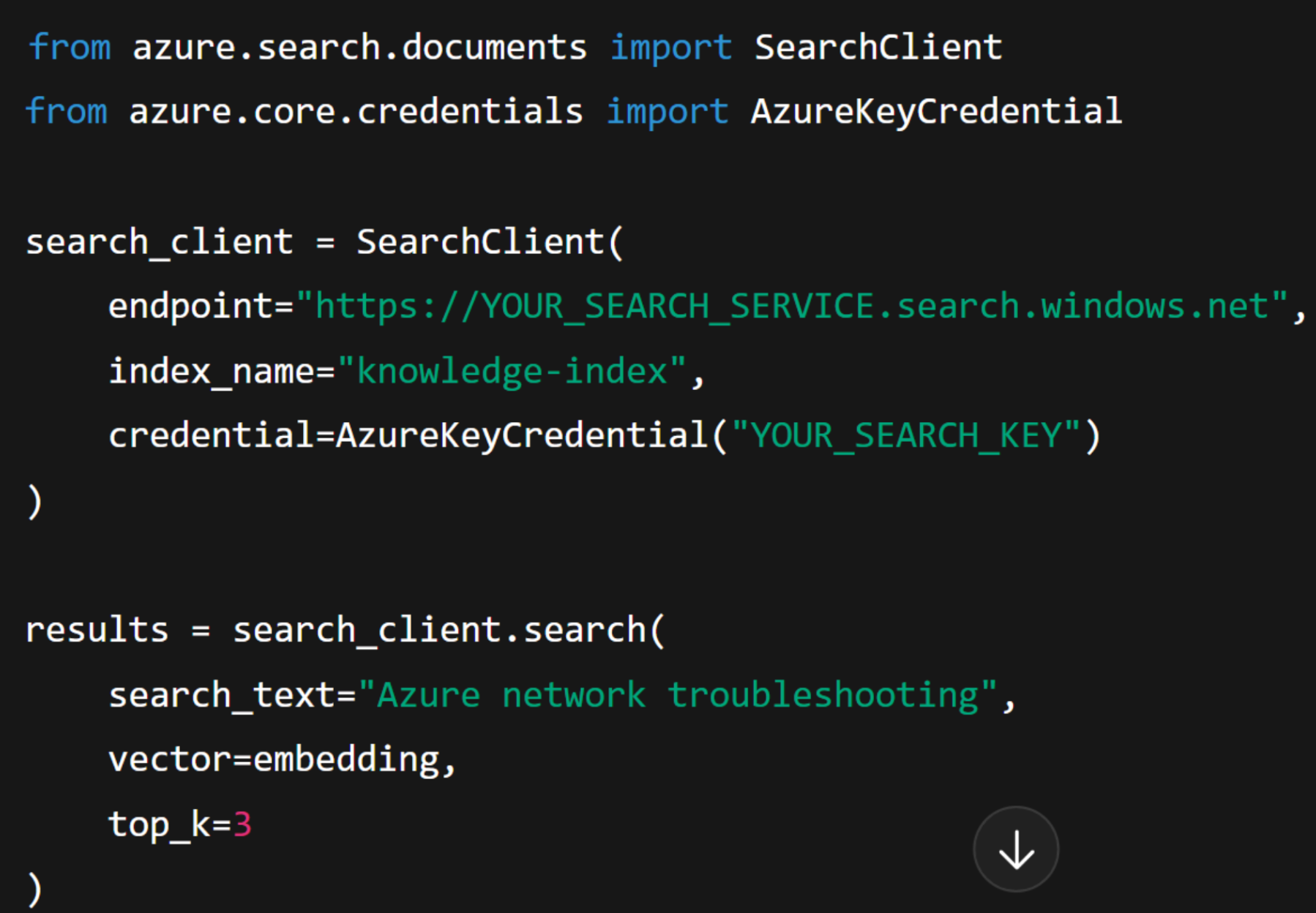
When a query arrives, the system uses these embeddings to perform a hybrid search that combines keyword relevance with semantic similarity. This ensures that even if users phrase questions differently, the retriever still identifies the most relevant documents.
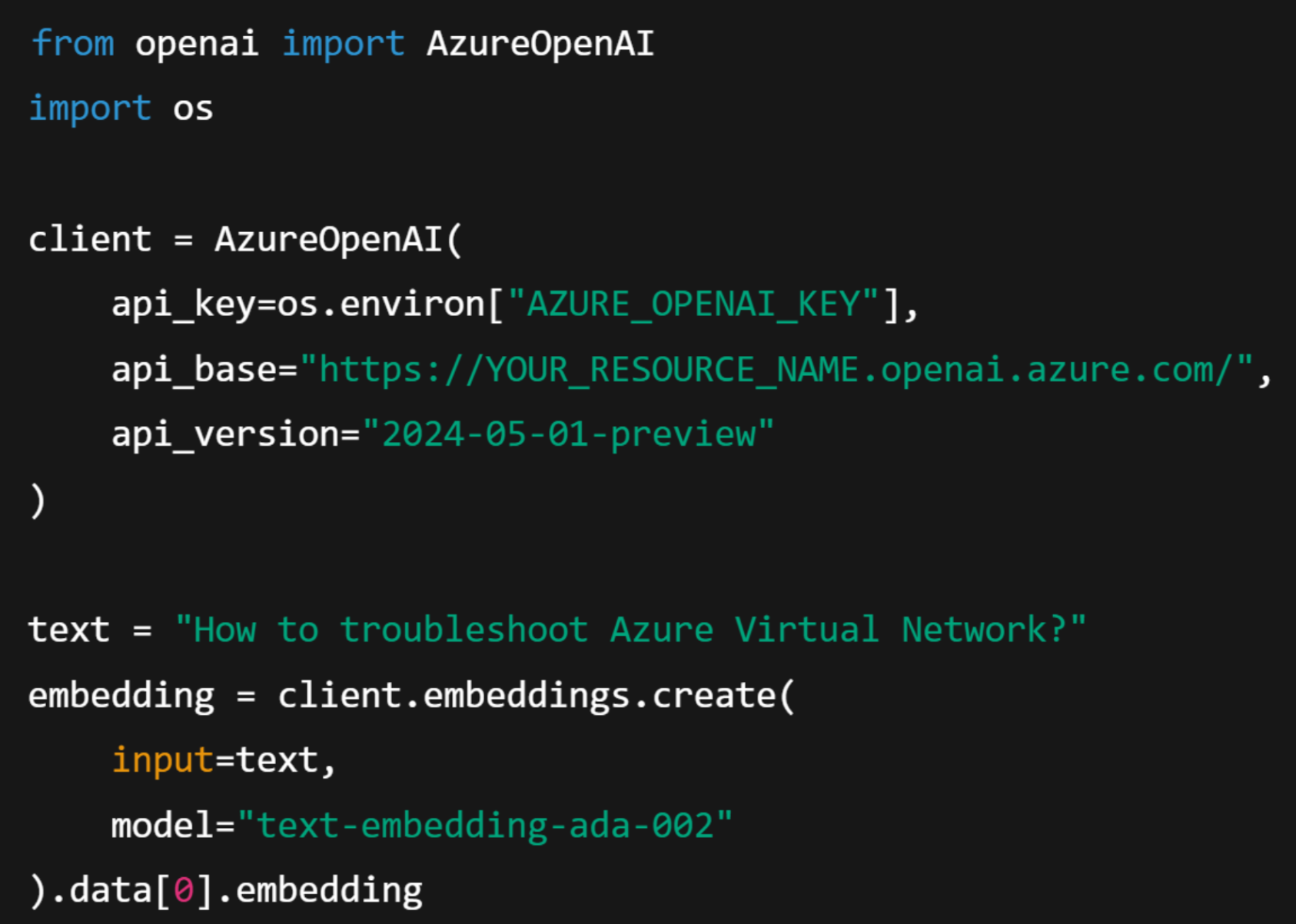
After generating embeddings, the retrieval phase queries the index. In this phase, Azure AI Search combines both vector and keyword signals to deliver top results that are then passed into the prompt.
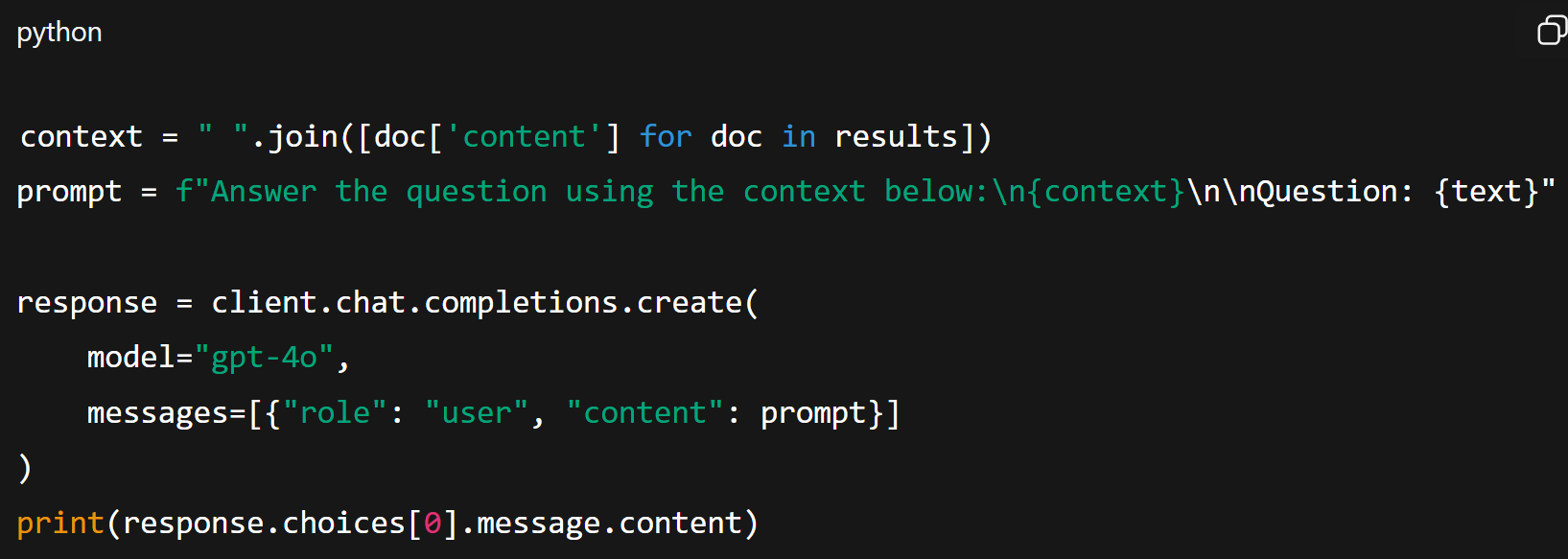
Once the relevant context is retrieved, the system transitions to the generation of the next step. The retrieved text is concatenated into a single context prompt that guides the model in formulating an accurate and context-aware answer.
Finally, Azure AI Foundry offers observability tools such as Prompt Flow, Trace Studio, and Model Monitoring. These allow teams to trace each request, validate retrieval accuracy, and evaluate latency. This operational transparency is essential for SMBs seeking to move beyond experimentation and into stable, production-grade deployment.
Why RAG Matters for SMBs
For small and mid-sized organizations, one of the biggest challenges in deploying AI lies in maintaining trust and factual consistency. Traditional models, trained on generic datasets, often produce plausible but inaccurate answers. RAG overcomes this by anchoring every response in verified company data. This ensures that AI-generated knowledge reflects the organization’s actual policies, products, and procedures.
In practice, RAG enables new levels of efficiency across departments. Customer support teams can automate responses that cite official manuals instead of relying on generalized model knowledge. Knowledge management teams can enable employees to query internal documents in natural language across SharePoint or Teams. Compliance officers can quickly find references to regulatory clauses in lengthy contracts, while sales teams can generate up-to-date product insights drawn directly from approved content. Each of these cases demonstrates how RAG bridges generative capability with trustworthy data governance on Azure.
Best Practices for Building Reliable RAG Systems
When implementing RAG for production, attention to data freshness is vital. Organizations should re-index their data periodically to ensure that recent policy updates or new documents are reflected in search results. Optimizing the size of text chunks also matters.
Monitoring quality is another critical step. Azure AI Foundry’s evaluation tools allow teams to measure how well the model’s responses align with retrieved facts through metrics such as Faithfulness. These insights can help teams adjust their chunking strategy, retrieval thresholds, or prompt design. Finally, enforcing responsible AI practices should not be optional. Azure AI Content Safety provides safeguards to filter sensitive or inappropriate content, helping organizations maintain compliance and user trust across jurisdictions.
Common Implementation Challenges
Teams new to RAG often make similar mistakes that limit scalability or accuracy. One frequent issue is neglecting embedding version control, which leads to inconsistent results when embeddings are updated. Another is feeding too many documents into prompts, which increases cost and reduces focus in generation. Performance issues can also arise when embeddings are recomputed unnecessarily rather than cached. Addressing these challenges early helps SMBs establish a stable foundation before expanding RAG usage to more complex workflows.
Partner with Precio Fishbone to Accelerate Your AI Transformation
At Precio Fishbone, we empower organizations to unlock the full potential of Azure AI through secure, production-grade implementations. Our expertise spans AI architecture design, data integration, model governance, and Copilot customization, helping businesses move from experimentation to measurable impact.
Whether you aim to enhance knowledge management, automate customer interactions, or scale intelligent decision-making across departments, our AI Solutions team can help you build responsibly and deploy confidently on Azure.
Discover more about Precio Fishbone’s AI Solutions: Talk to your consultant
Can RAG be built without using Azure AI Search?
It is technically possible to use other databases for retrieval, but Azure AI Search offers native integration with Azure OpenAI, hybrid search capabilities, and enterprise-grade security that simplify development and scaling.
Does RAG eliminate hallucinations completely?
It significantly reduces them by grounding responses in a factual context. However, no generative model is entirely immune to hallucination, so continuous monitoring and evaluation remain essential.
How often should an organization reindex data?
Dynamic data, such as support articles or product documentation, benefits from weekly indexing, while static data, like policies or manuals, can be updated monthly.
Share this on

Jerry Johansson
Jerry Johansson is a technical writer and IT consultant who makes complex technology understandable – and practical. He helps organisations turn digital tools into everyday value.